Few-Shot Learning, Prompt Selection, Similarity Search, Maximal Marginal Relevance (MMR), Reranking, Cross-Encoder, In-Context Learning, Large Language Models, Retrieval Strategies, Mistral-8B, Phi-4, Gemini Flash 2.0
Enhancing Few-Shot Learning Through Optimised Prompt Selection: Reranking vs. MMR and Similarity Search
Morice NouvertneMy recent paper dives deep into this question, offering a comprehensive evaluation across multiple NLP tasks, including sentiment classification (SST2, SST5, Emotion), topic classification (AG News), question classification (TREC), and causal reasoning (e-CARE). Leveraging three powerful LLMs—Mistral-8B, Phi-4, and Gemini Flash 2.0—I systematically compared three retrieval strategies: similarity search, MMR, and transformer-based reranking.
In the rapidly evolving field of AI, effectively guiding large language models (LLMs) through few-shot learning hinges critically upon selecting the right prompts. While traditional similarity-based methods provide quick and straightforward retrieval of prompt examples, the question remains: Could more dynamic approaches, such as reranking or Maximal Marginal Relevance (MMR), yield even better results?
Why Does Prompt Selection Matter?
Prompt examples significantly influence the accuracy and efficiency of LLM responses, especially under constraints where models receive minimal input guidance (few-shot learning). Traditional methods often prioritise semantic similarity alone, but recent advances suggest that balancing both relevance and diversity might yield more robust outcomes.
Pipeline Architechture
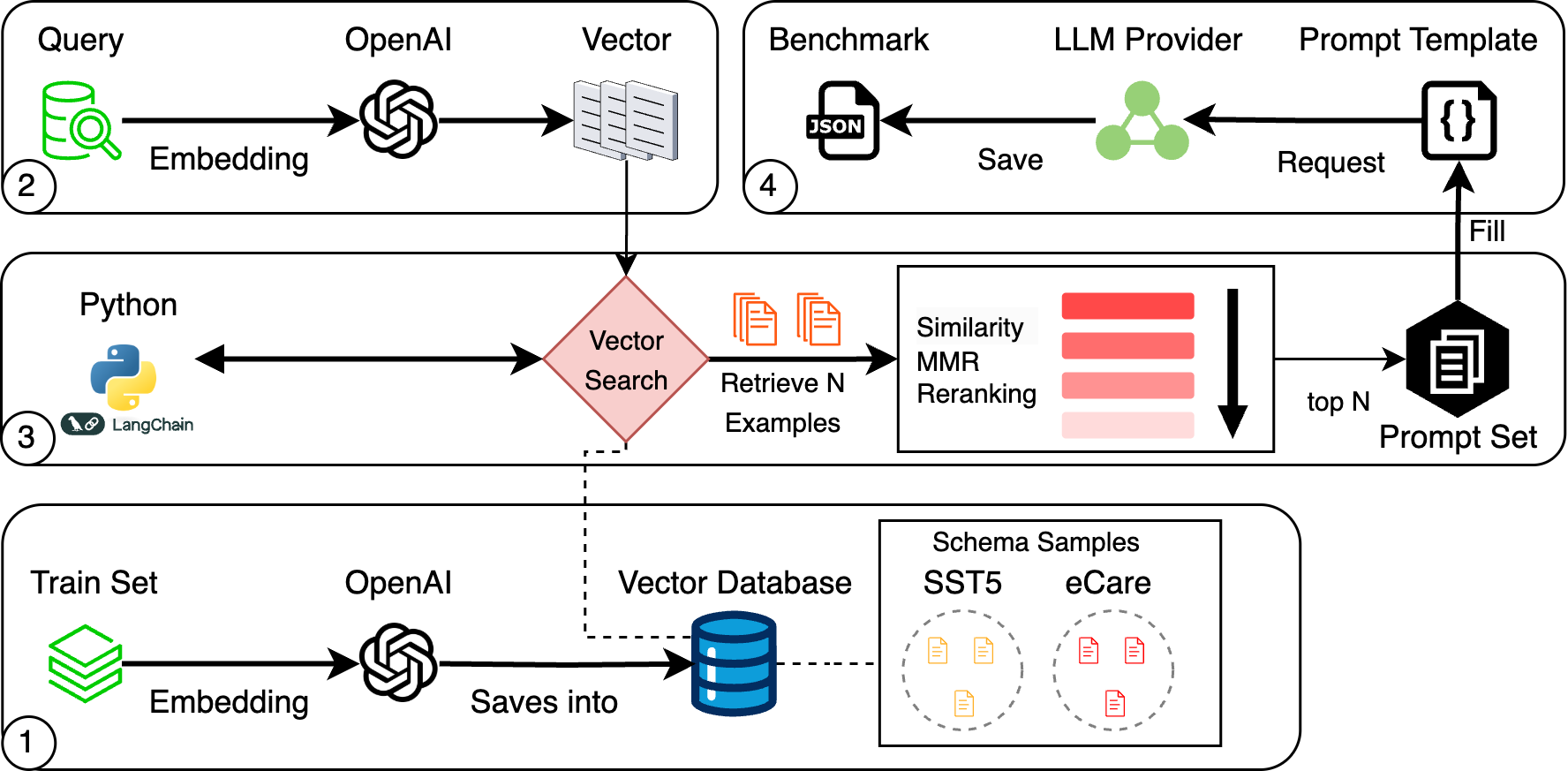
Methodology and Innovations
This study introduced a structured retrieval pipeline leveraging OpenAI embeddings and vector databases, complemented by sophisticated reranking with cross-encoder models. Specifically, we compared:
- Similarity Search: Fast and precise, ideal for closely structured tasks.
- Maximal Marginal Relevance: Balances similarity and diversity, aiming to broaden context exposure without redundancy.
- Cross-Encoder Reranking: Dynamically refines retrieved candidates to closely match query semantics, albeit at a higher computational cost.
Key Findings and Insights
Our results were illuminating:
- Reranking consistently outperformed similarity search and MMR, delivering an impressive average accuracy improvement of 4.75% over basic similarity retrieval across diverse NLP tasks.
- Interestingly, e-CARE—focusing on causal reasoning—favoured simpler similarity search, likely due to its structured nature where direct semantic alignment provided more benefit than diversity-oriented methods.
- Smaller models benefited significantly from retrieval refinement, whereas larger models like Gemini Flash exhibited stable performance irrespective of method, highlighting a nuanced relationship between model scale and retrieval technique effectiveness. These insights underline that the choice of retrieval strategy should align closely with both the task specifics and the characteristics of the deployed language model.
Practical Implications and Future Directions
Our research underscores the necessity for adaptive retrieval strategies in industry applications. Incorporating reranking can substantially enhance LLM performance, particularly in tasks where nuanced semantic matching improves outcomes, such as sentiment or complex topic classification. Conversely, simpler methods may remain optimal for well-defined semantic tasks, like causal reasoning. Future research will explore adaptive retrieval pipelines, dynamically adjusting strategies based on real-time data characteristics and model capabilities, promising even more robust and efficient AI deployments.
Citation
@inproceedings{nouvertne2025fs,
title = {Enhancing Few-Shot Learning Through Optimised Prompt Selection: Reranking vs. MMR and Similarity Search},
author = {Nouvertne, Morice and Molinari, Marc and Andritsch, Jarutas and Ahmad, Shakeel},
year = {2025},
doi = {TBD}
}